
Datasets
Introduction
The Ambience Datasets module is responsible for providing data to other modules, for example Dashboard. A dataset is a named collection of records where each record consists of named values which may be not only text strings, numbers and booleans, but also arrays, binary data and even nested records. The data can be derived from three sources:
- MongoDB dataset where it reads data from MongoDB databases.
- ETL dataset where it reads data from ETL chainsets.
- Dataset itself where it reads data from other existing datasets.
Module Interface
The interface of the Datasets module.

Add Dataset
To create a new dataset, click the “Add” button located at the upper right corner of the page.

The “Add Dataset” dialog box will appear.
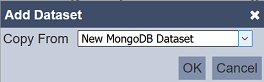
In the “Copy From” field, select which dataset’s source to be used from the dropdown list.
Screenshots below shows the Properties setting for both MongoDB dataset and ETL dataset.
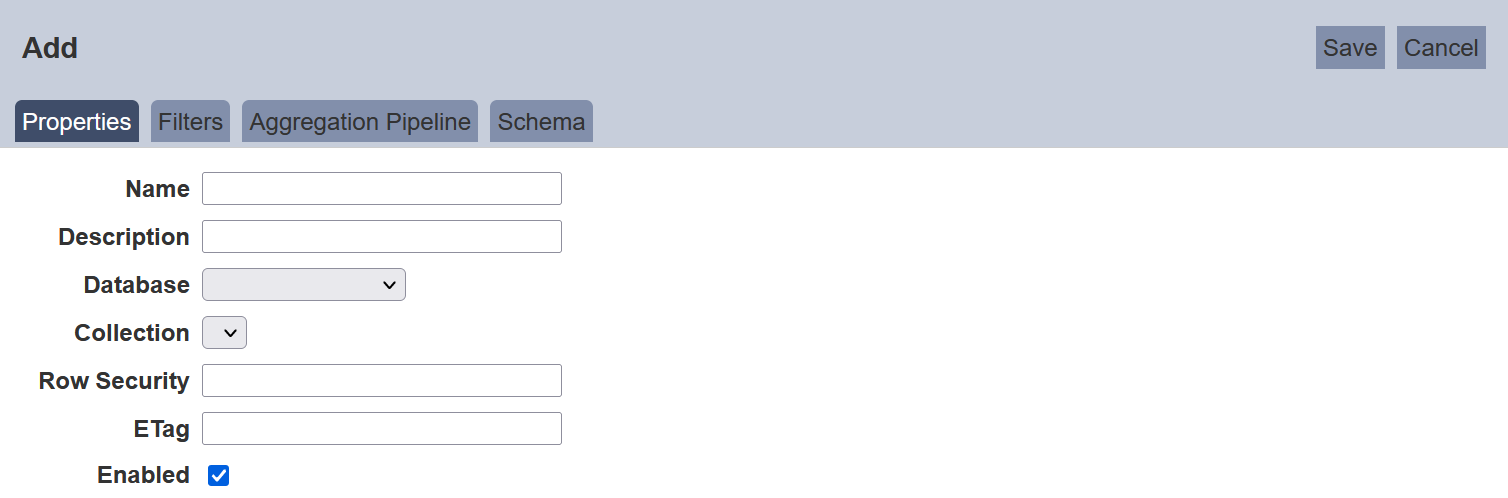
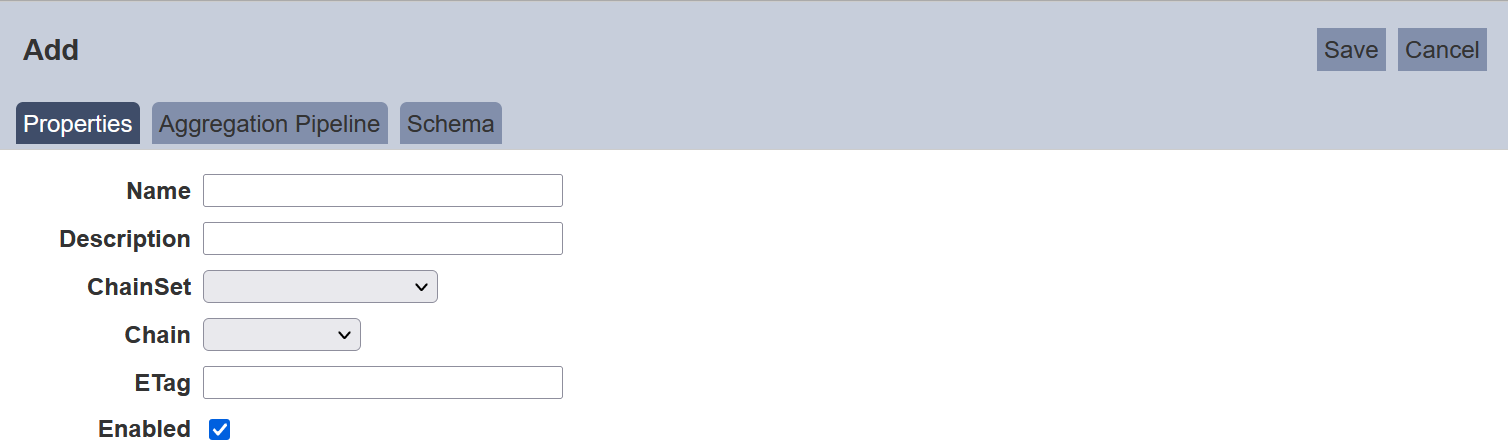
Properties Tab
The following is the basic setup for a new dataset. The interface looks different between MongoDB dataset and ETL dataset.
| Field | Description |
|---|---|
| Name | A unique dataset name. (Required) |
| Description | Additional text to describe the dataset. (Optional) |
| Database | The database that holds the collection used as the source of records for this dataset. Choose from the list of databases which is based on the MongoDB database setting in the Ambience application.conf file. (Required for MongoDB datasets) |
| Collection | The collection (table) used as the source of records for this dataset. Choose from the list of collections. (Required for MongoDB datasets) |
| Row Security | Checks the credentials of user to determine which rows of data are to be displayed for that user. (Optional) If undefined, all data is displayed. If user does not have the credentials, no data wil lbe displayed. |
| ChainSet | The ETLs (chainset) created in ETL module. Choose one from the chainset. (Required for ETL datasets) |
| Chain | The chains with Dataset Endpoint step in the selected ETL used as the source of records. Choose from the list. (Required for ETL datasets) |
| ETag | Use to reflect the dataset has changed since its last datetime. By default, it is blank when a dataset is created. (Optional) |
| Enabled | Status of the dataset. It is “Enabled” by default. (Required) |
Example: Using Row Security
The “Row Security” feature allows access rights control on the dataset. It applies to MongoDB dataset only. If no field is defined, all data will be displayed in the views in the dashboard that uses the dataset. If a field is defined, users with the correct credentials will view the appropriate data in the views in the dashboard.
To do so, in the Datasets page, click on the  “Edit” icon under the “Actions” column corresponding the desired dataset. in the “Properties” tab, key in the field that you wish to control. The field name must be part of the schema. In the example below, the field “Region” is selected as the control.
“Edit” icon under the “Actions” column corresponding the desired dataset. in the “Properties” tab, key in the field that you wish to control. The field name must be part of the schema. In the example below, the field “Region” is selected as the control.
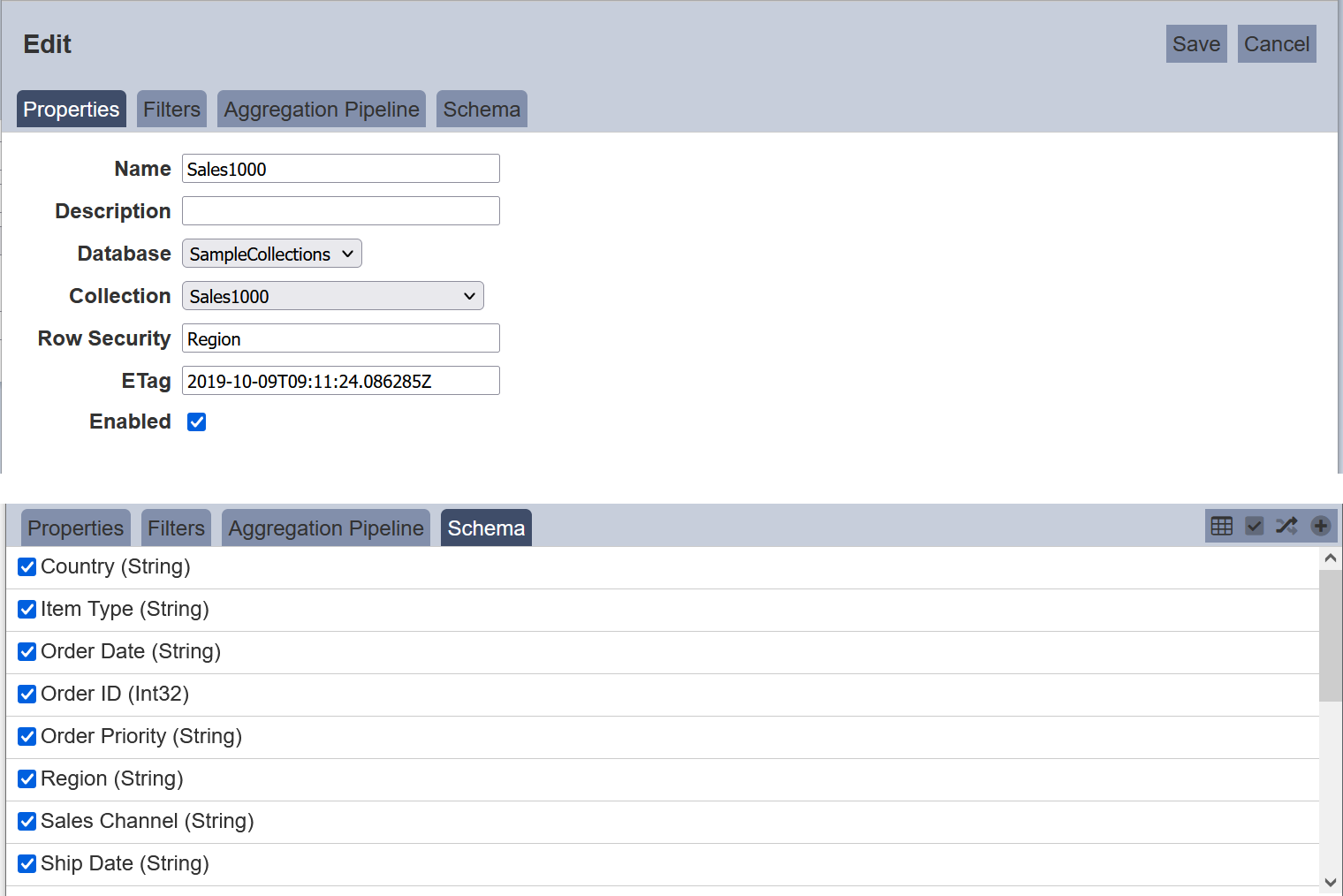
Click on the “Save” button to save the change. The options for the field “Region” now can be used as values to check against users credential values.
In the Roles page, create roles using the options for “Region”. In this example, UserA is granted the role “Europe” while UserB is granted the role “Asia”. Admin is granted both “Asia” and “Europe” roles. UserA and User B will only see data for their own region, which is Asia and Europe respectively. Admin will see 2 sets of data, from Asia and Europe.

Filter Tab (MongoDB Dataset only)
Ambience Datasets module supports comparison query operators such as equal, greater than or equal, etc. The filter is an optional step, where one of the operators can be selected from the dropdown selection to perform a quick filter on a field in the collection. The filter is applied to the collection data before aggregation.
Aggregation Pipeline Tab
Aggregation pipeline processes or transforms documents (records) into an aggregated result, for example, a MongoDB syntax below is used to unwind an array of field from documents,
db.inventory.aggregate( [ { $unwind : "$sizes" } ] )
However, in Dataset Management, you write the aggregation pipeline with JSON syntax as below to perform the same operation,
[ { "$unwind" : "$sizes" } ]
Aggregation pipeline validates the JSON syntax and shows the test results on the right-side panel. The benefits of aggregation pipeline are,
- All data processing is done inside MongoDB including those datasets which use the ETL chainsets.
- Aggregation pipeline operations have an optimization phase which attempts to reshape the aggregation pipeline for improved performance.
- Network traffic to the client is smaller.
Aggregation pipeline is optional for both MongoDB dataset and ETL dataset. You can click on the “Test Aggregation” button even without writing aggregation to show the result. More examples as below,
Sample 1: Deconstruct an array field fom the input documents to a document for each element using $unwind.
Consider a collection with following document,
{ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] }
The following aggregation uses $unwind to output a document for each element in the sizes array.
[{ "$unwind" : "$sizes" }]
Each document is identical except for the value of sizes, hence, it returns three lines.
{ "_id" : 1, "item" : "ABC1", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "L" }
Sample 2: Use of $project and $group to group a field not equal to 1 and get a count.
$project takes a document that specifies the inclusion of fields, the suppression of the "_id“ field, the addition of new fields and the resetting of the values of existing fields. For example, $project takes ”patient_name" field in its output documents. Then, selects documents to process using $match operator, in this case not equal to 1, and returns the results in the $group operator to compute a count of documents.
[
{
"$project" : {
"patient name" : 1
}
},
{
"$group" : {
"_id" : "$patient name",
"count" : {
"$sum" : 1
}
}
},
{
"$match" : {
"count" : {
"$ne" : 1
}
}
}
]
Sample 3: Using of $elx prefix.
The “$elx” prefix is used in aggregation pipeline where operators need to be used but are not recognised in MongoDB. These prefixed operators are are handled by the dataset pre-processor and removed before passing to MongoDB for evaluation.
The below code
[
{
"$elx-parameter" : {
"name" : "ABC",
"value" : {"anything" : true}
}
},
{
"$match" : {
"elx-lookup" : "ABC"
}
}
]
will become
[
{
"$match" : {"anything" : true}
}
]
when passed to MongoDB. If there are several parameters with the same name, the first parameter will be chosen.
Schema Tab
Infer schema shows all the fields in the dataset based on the filter and/or aggregation, except fields start with "_“ by default, for example, ”_id“ and ”_metadata“ (used by the Imports module). There are options to include these fields by clicking the ”Expand“ button (Show Intervals) and invert selection in the dataset by clicking the ”Invert Selection" at the top right of the panel. There is a warning if you attempt to save the dataset setup without inferring the schema. Also, after changing the Aggregation Pipeline, the schema may change and it should be inferred again.
You can hover over the fields to see enumerated values if there are less than X values (where X is defined in config as ambience.datasets.choices.limit = 100). For example “Monday”, “Tuesday”, etc. if you hover over DayOfWeek (DOW) field,
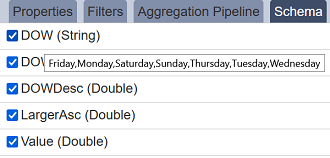
Subset Dataset
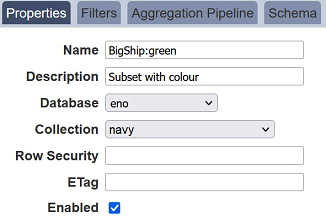
Datasets can be broken down into subset with different filter criteria and/or aggregation pipeline by using a colon to distinguish a subset from a dataset, for example, BigShip:green where green is the subset of the BigShip dataset. If the BigShip dataset does not exist, the BigShip:green becomes a dataset instead of a subset.
ETag
The Etag reflects when the dataset has changed by checking the last modified datetime. Etag works with the ETL Bump Etag step which updates new datetime in the Datasets module’s Etag column. Alternatively, Etag can be manually updated by clicking the  “Update Etag” icon under the “Actions” column corresponding the desired dataset.
“Update Etag” icon under the “Actions” column corresponding the desired dataset.

Upload Dataset
Upload allows importing the DayTest.dataset.json file into Datasets module in another machine and provides the option to create a new dataset or overwrite an existing one. To upload a dataset, click on the “Upload” button located at the upper right corner of the page.
The “Upload Dataset” dialog box will appear.
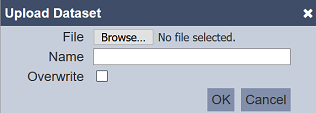
| Field | Description |
|---|---|
| File | Browse to the location of the file. (Required) |
| Name | A unique dataset name. (Required) |
| Overwrite | Selected to overwrite existing dataset. By default, this field is deselected. |
Browse to the location of the file to be uploaded in the “File” field. In the “Name” field, key in a unique name for the dataset if it is a new dataset. If the file to be uploaded is to overwrite an existing dataset, ensure to select the “Overwrite” field and key in a name that matches the dataset to be overwritten. Click on the “OK” button to upload the dataset or click on the “Cancel” button to abort the action.
Edit Dataset
In edit mode, you can perform,
- enable or disable the dataset.
- edit properties, filter, aggregation pipeline and schema.
To edit a dataset, click on the “Edit” icon under the “Actions” column corresponding the desired dataset.
The “Edit” panel will appear.
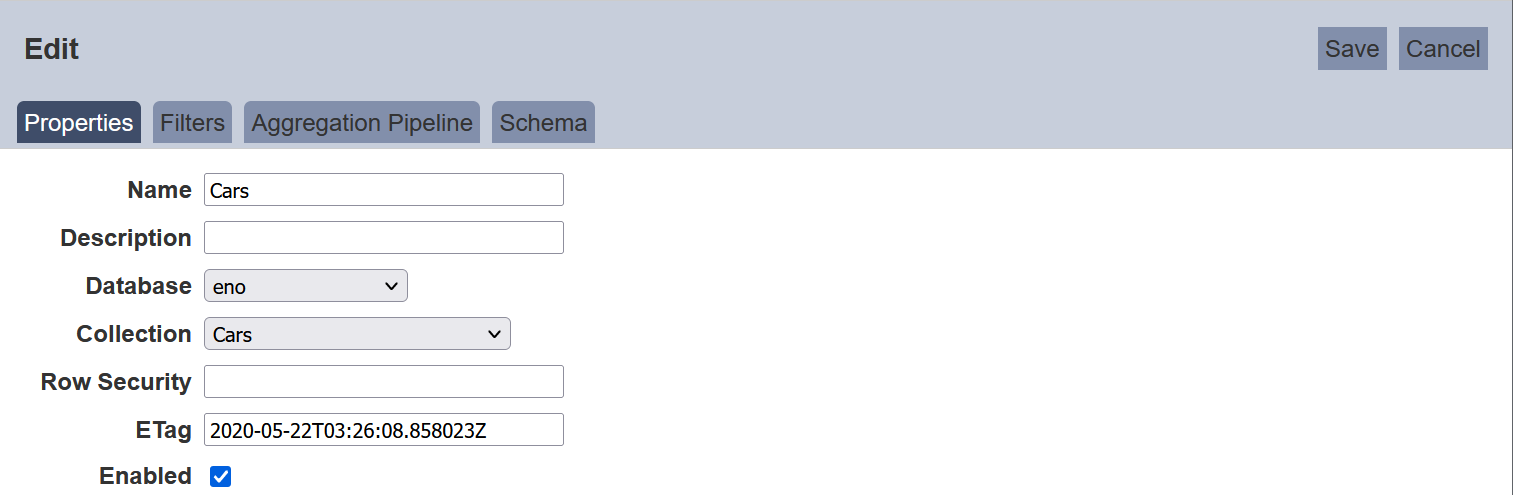
Edit as required and click on the “Save” button to save the changes. Click on the “Cancel” button to abort the action.
Download Dataset
The download allows exporting dataset’s settings in Datasets module into a .json file, for example, DayTest.dataset.json. To download a dataset, click on the  “Download” icon under the “Actions” column corresponding to the desired dataset.
“Download” icon under the “Actions” column corresponding to the desired dataset.
Delete Dataset
Delete function deletes a selected dataset in Datasets module, not delete the data.
To delete a dataset, click on the  “Delete” icon under the “Actions” column corresponding the desired dataset.
“Delete” icon under the “Actions” column corresponding the desired dataset.
There is an option to undo the deletion. A notification with an “Undo” button appears right after clicking on the “Delete” icon.
Upon clicking on the “Undo” button, the deleted dataset is restored and is added back to the list of dataset.
Refresh
After performing actions on the browser/tab, the list is reloaded to display the list of datasets in the page. The manual “Refresh” button is available and is particularly useful if you or others have opened multiple pages and making changes.
The “Refresh” button is found at the upper right corner of the page. Clicking on it reloads the list.
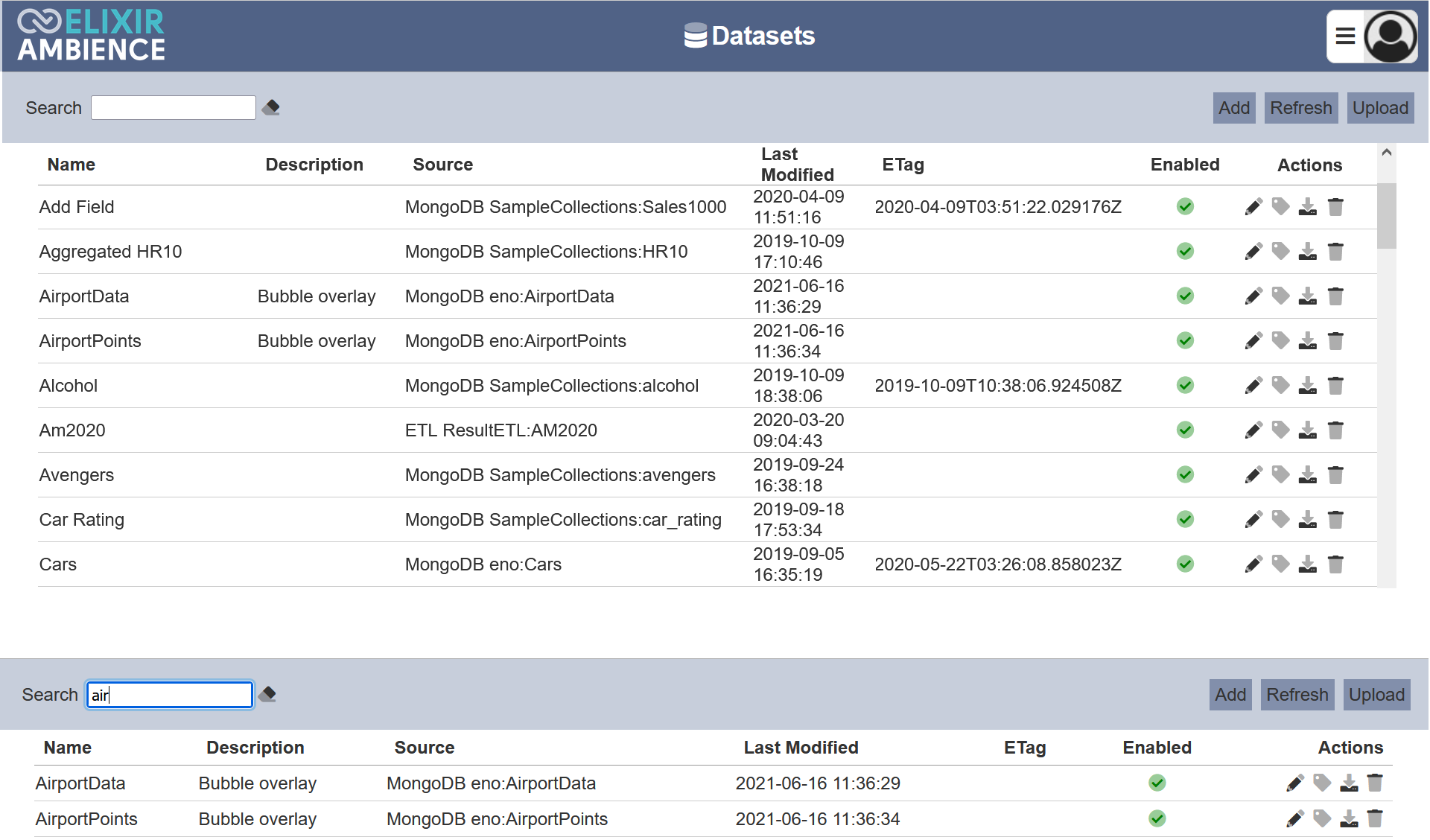
Search Dataset
The search function at the top left of Datasets module page, filters the dataset list retaining those with matching text.

This provides an easy way to search through the list of dataset. It is case-insensitive and displays the datasets that have the entered search value in any of the values of the fields below:
- Name
- Description
- Source
- Last Modified
- ETag
Dataset Data
When adding or uploading a dataset, the dataset does not include the data, only the dataset “Definition”, including the schema. The data need to be imported into the dataset. There are two methods to import the data.
- Import module - import the data , as well as creating the dataset (see Import module)
- Repository module - generate data using ETL chainset with datasource already deposited in the module
Below is a simple method to use ETL chainset to generate and load the data into the dataset.
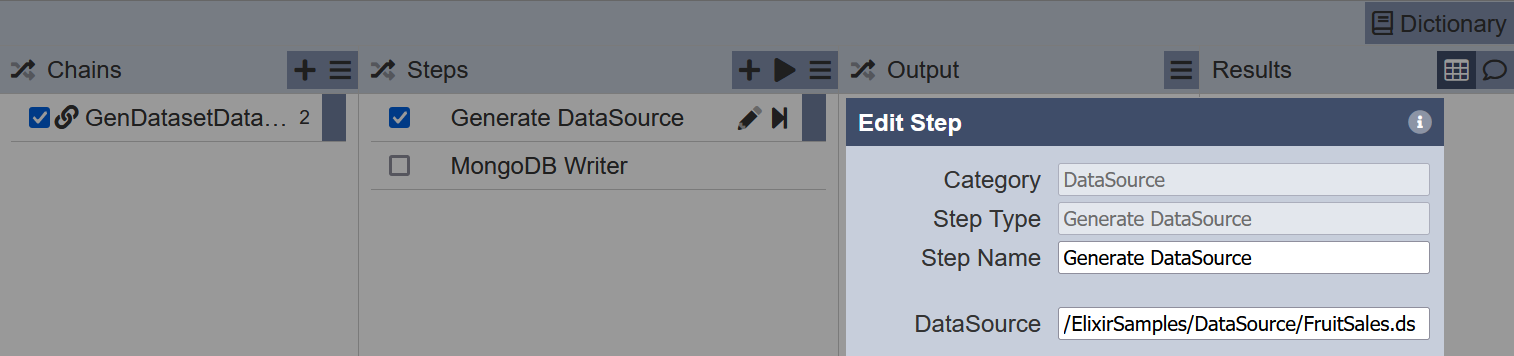
Create a ETL chainset with Generate DataSource and MongoDB Writer ETL steps.

In the first ETL step, key in the location of the datasource in the Repository module.
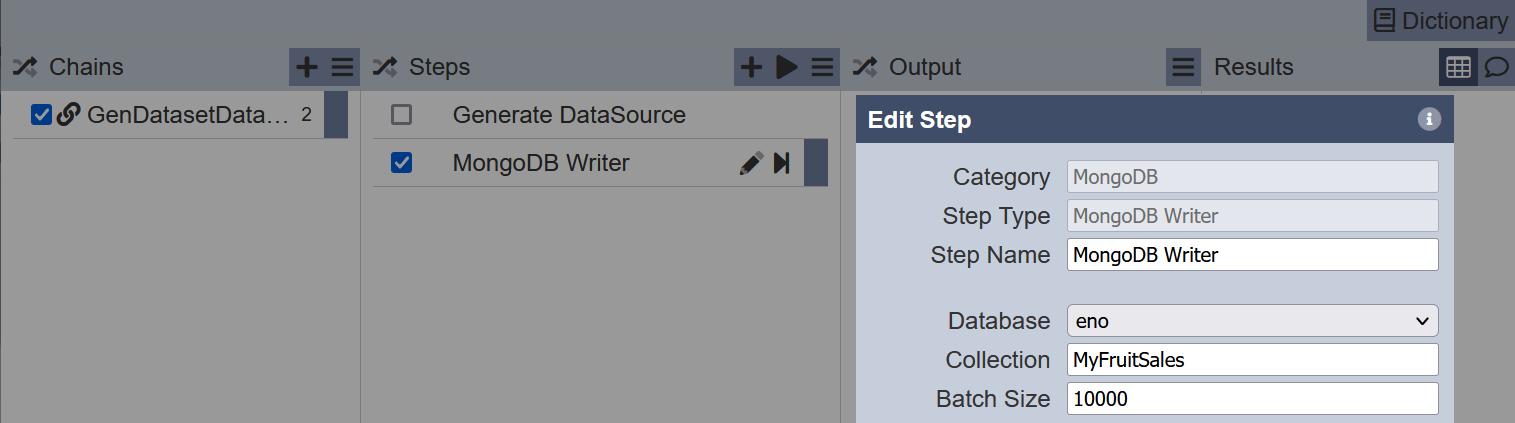
In the second step, key in the dataset to add the data into.
Click on the “Run Steps” icon at the upper right corner of the Steps column.

Check the data in the dataset using the Developer module.

You can combine Generate DataSource with a Dataset Endpoint ETL step if you want to wrap a datasource as a dataset. Hence you can se the datasource as a dataset as well.