
Processor
The ![]() Processor is a generic processor that allows certain specific data processing tasks to be executed. These tasks are designed to be easily customised in different versions of the tools.
Processor is a generic processor that allows certain specific data processing tasks to be executed. These tasks are designed to be easily customised in different versions of the tools.
The standard processors are:
| Processor | Description |
|---|---|
| Cleansing | |
| Remove Duplicates | Removes records where certain key fields are duplicates. |
| Validation | Checks records against column attribute constraints and appends columns detailing validation failures. |
| General | |
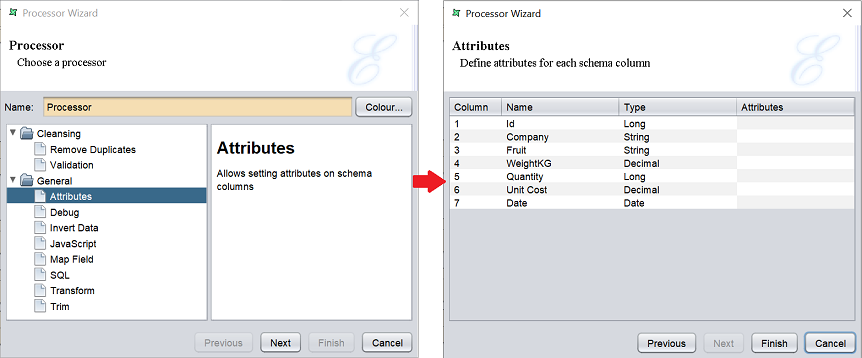
| Attributes | Allows setting attributes on schema columns. |
| Debug | Outputs debugging messages to the log. |
| Invert Data | Allows record data to become columns in an inverted schema. |
| JavaScript | JavaScript controlled record processor. |
| Map Field | Map the field to a different name base on another source. |
| SQL | Execute SQL commands upon chosen events in the flow. |
| Transform | Applies efficient transformations to records. |
| Trim | Trims all string fields. |
Add Processor
To add a Processor onto the digram, select the ![]() button on the menu bar and click on the location in the designer diagram. Use the Flow connector to connect the Processor and other processors together.
button on the menu bar and click on the location in the designer diagram. Use the Flow connector to connect the Processor and other processors together.
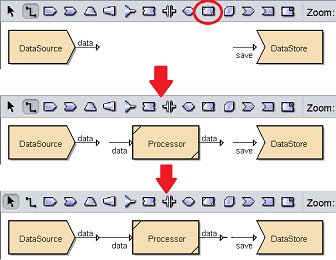
The Processor is present but the type of processing method is not defined yet. The Processor data to the DataStore processor is a dotted line, which means there is no output data as the Processor is not defined.
Edit Processor
After the processors are connected together, edit the Processor to define the type of processing task.
There are two ways to access the Processor.
- Double-click on the Processor
- Right-click on the Processor and select the “Properties” option from the pop-up menu
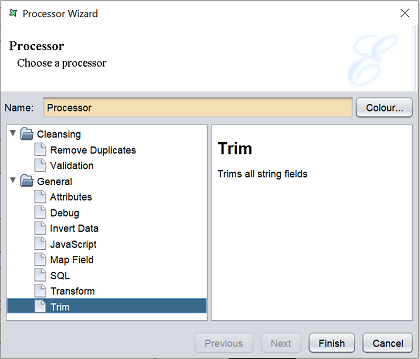
Either one method will launch the Processor Wizard.
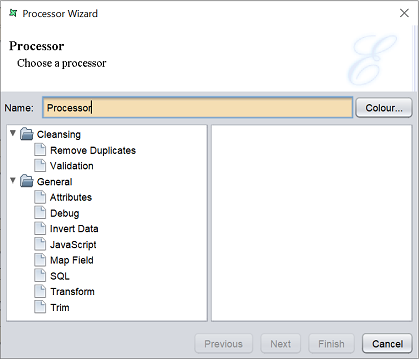
The Processor Wizard allows you to select the type of processing task. The type of processing task can be divided into two groups:
- Cleansing
- General
Cleansing
Remove Duplicates
This task removes duplicate records. A duplicate record is determined by a set of key fields being the same. The set may contain a single field (e.g., identify card number), or a collection of fields (e.g., name and address). The fields are chosen by selecting a checkbox next to the appropriate items in the “Test” column of the schema table.
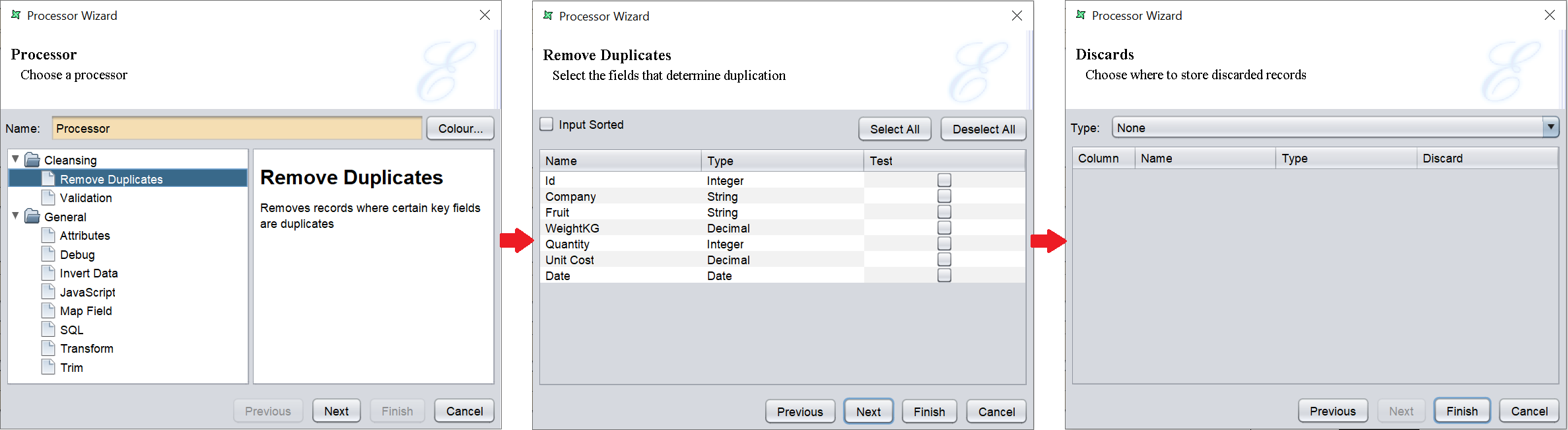
Whenever subsequent records are identified as being duplicates of those already processed, the later records are always discarded. This means only the first record with a given set of key fields will be passed through. If the records are sorted such that duplicate records are adjacent, you should tick the INput Sorted checkbox so that the system can use an alternate algorithm to reduce memory usage. When the “Input Sorted” field is selected, each record is only compared against the previous record, instead of all previous records, resulting in faster performance and reduced memory requirements.
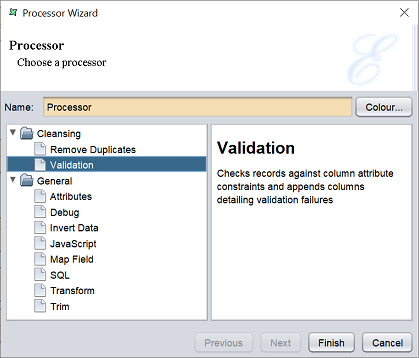
Validation
This task checks records against column attribute constraints and shows error messages of column attributes fail to pass the validation. The output of the validation is shown in two fields.
elx.validation.FailCount(Integer)- Counts the number of failures in each rowelx.validation.FailMessages(String)- Shows the failed attributes and column names
General
Attributes
This task allows the user to specify attributes in a convenient way.
To specify an attribute, click on the cell under the “Attributes” column of the desired field. A “Data Attribute” dialog box will appear, which allows you to add an attribute or edit/remove an existing attribute.
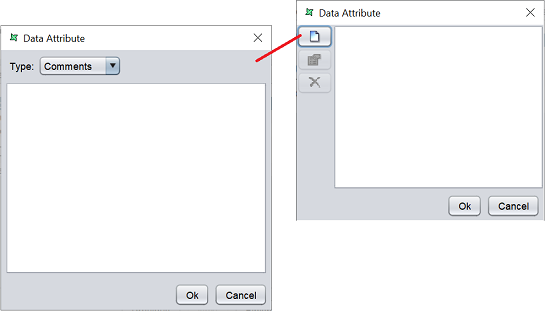
Click on the “Add” button to add a new attribute. Another dialog box will appear. Select the desired type from the drop-down list.
| Attributes | Description |
|---|---|
| Comments | Enter text for comments in the textbox. 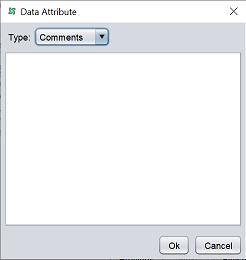 |
| Enumeration | By defining the attributes of individual fields, the Data Designer can then validate the record values using the cleansing process. For example, we might specify that the field “Gender” is a nominal enumeration of “M” and “F”. The cleansing process would then warn us of any records containing “m” or “Female”. Ordinal enumeration attributes allows us to specify the order to display data, while retaining the original order. For example, we might specify that the field “Fruit” is an ordinal enumeration of “Apple” and “Orange”. Only “Apple” and “Orange” records can pass the validation in the cleansing process. 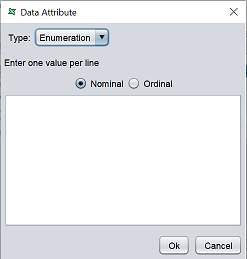 |
| ForeignKey | This type of attributes is created by JDBC DataSources, and therefore cannot be edited. 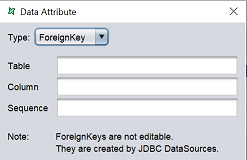 |
| Format | Define the format. 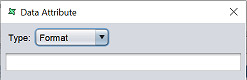 |
| Nullable | Specify whether the data can be Null values. 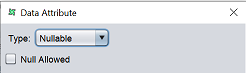 |
| PrimaryKey | Complete a uniqueness check that all keys should be unique. 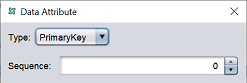 |
| Range | Specify the start and end values. 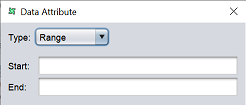 |
| RegExp | Define and test syntax. 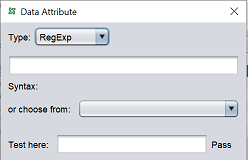 |
Debug
This task allows the user to monitor the flow of records through the console without having to stop the flow. From there, the user will be able to know where the problem lies and resolve the issue.
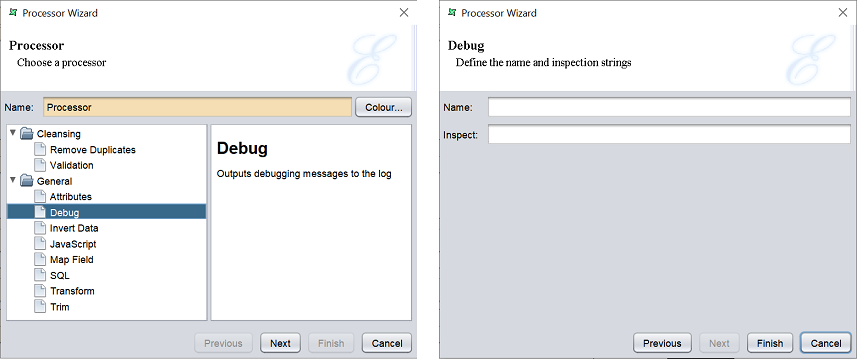
Before being able to see the data flow through the console, the user will need to edit log-conf.xml. Look out for the following in the file and change INFO to DEBUG.
<logger name="comm.elicirtech.data2">
<level value="INFO" />
</logger>
This task is usually used after another processor which processes the data and it is at this stage where data gets messed up. Therefore, with the use of processing task, it will be easier to point out the source of the problem.
Invert Data
This task inverts the data records so that the rows become the columns and vice-versa. In order to convert the rows to columns, one original column must provide the names of the columns in the new schema. This column should contain unique values to ensure the resulting schema does not have duplicate column names. Select the column that will provide the column names at the top of the wizard.
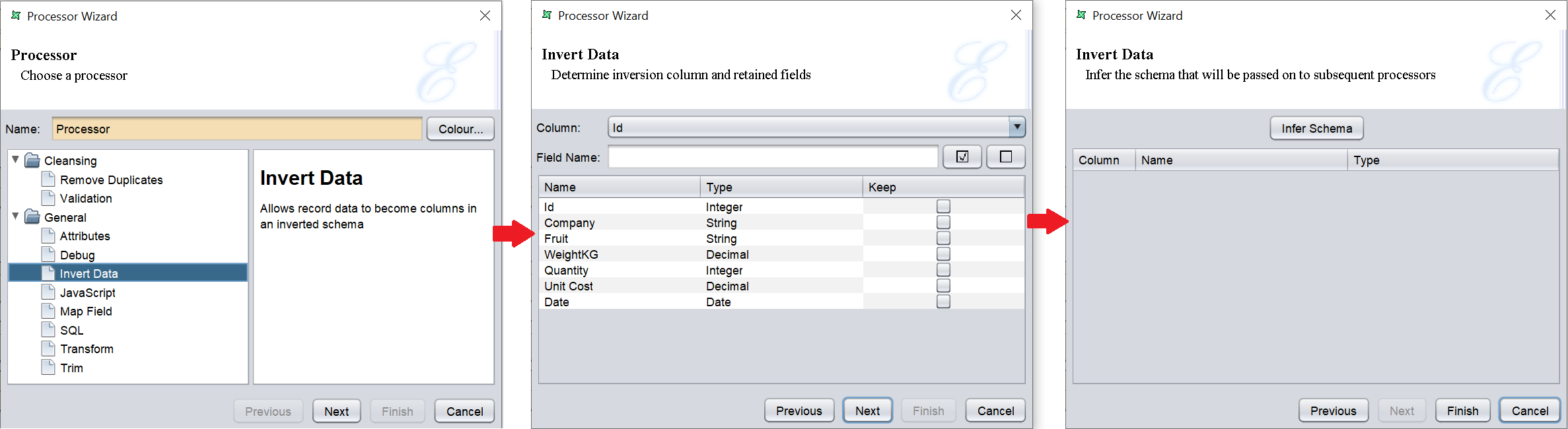
Conversely, the old columns names may be retained as row values. If so, enter a field name in the next text field, otherwise leave it blank. Specifying a name will adda a column in the output schema of the type String, whose values will be equal to the “Keep” column.
The next step is to identify which old columns to keep, those that should be mapped into the new inverted structure. The resulting dataset will contain only as many records as are marked “Keep”. Because each row becomes a column when inverted, the system will need to determine the appropriate column type in the output schema. Alternatively, if the selected columns contain mixed types, then the String type will be used in the output schema to ensure all values can be represented.
As an example, assume a simple table like this:
A B C D
1 2 3 4
5 6 7 8
Where A, B, C and D are column names. If we choose InvertColumn=B, FieldNAme=Field, Keep=A,D, then the output after Invert DAta will be:
Field 2 6
A 1 5
D 4 8
As the two columns were selected for keeping, there are two records in the output. The old column names are assigned to be the values of the new column called “Field” (the FieldName value), and the unique values of the B column (“2” and “6”) become the column names in the new schema.
JavaScript
This task allows the user to perform any kind of record operation or schema re-arrangement which might be too complicated for regular flows. With this processor, a user can now save a lot of complex joins, filters and concatenations which is required previously.
The scripts are to be entered in the text field in their respective tabs.
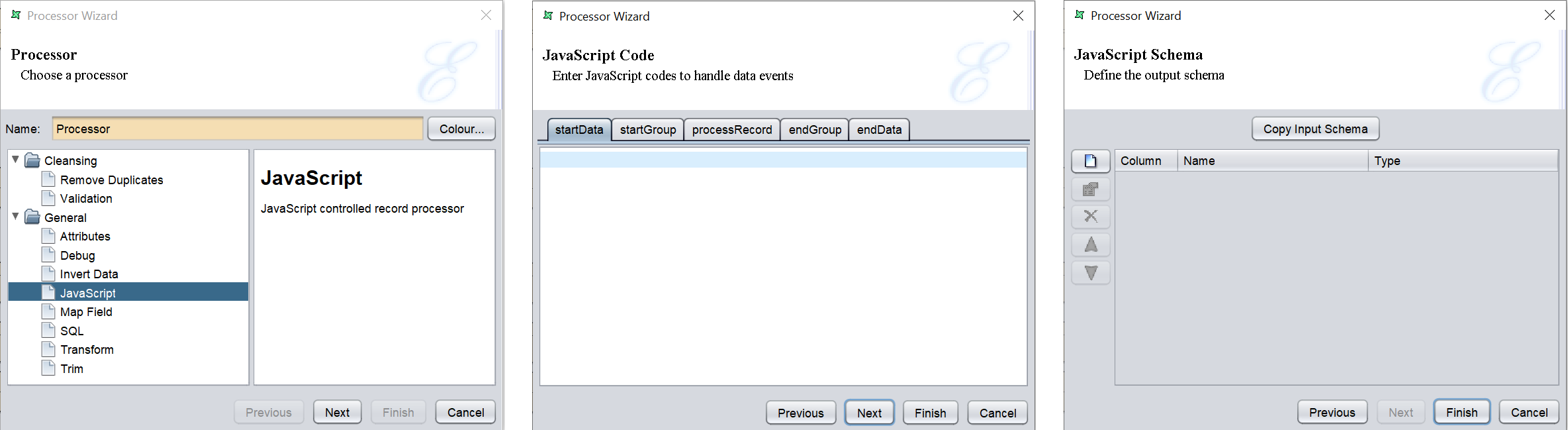
In the next page, you can define the output schema by either copying the input schema and/or add new fields individually.
Map Field
Using this option, we can reference to another datasource and use the field(s) in that datasource and make the composite datasource contain field(s) in that selected datasource. The field name can be amended if desired.
In the wizard, choose a datasource from the depository to reference. Then add the fields to map.
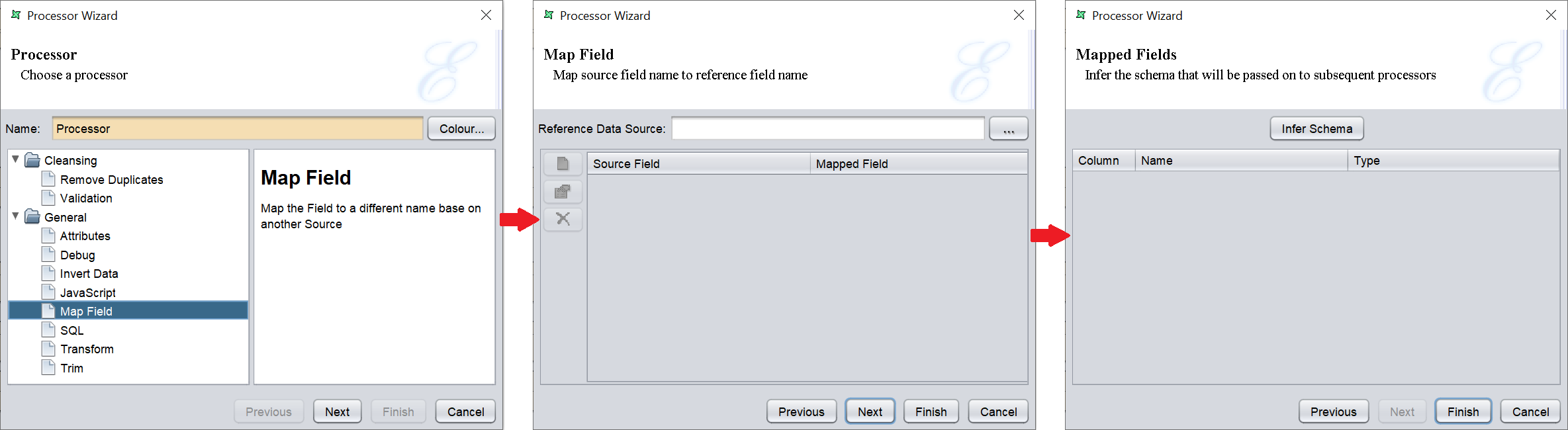
In the next page, click on the “Infer Schema” to view the new schema for the output.
SQL
This task allows the user to send any SQL commands to the database based on th standard flow events after a JDBC connection is set up on the second page of the Processor Wizard.
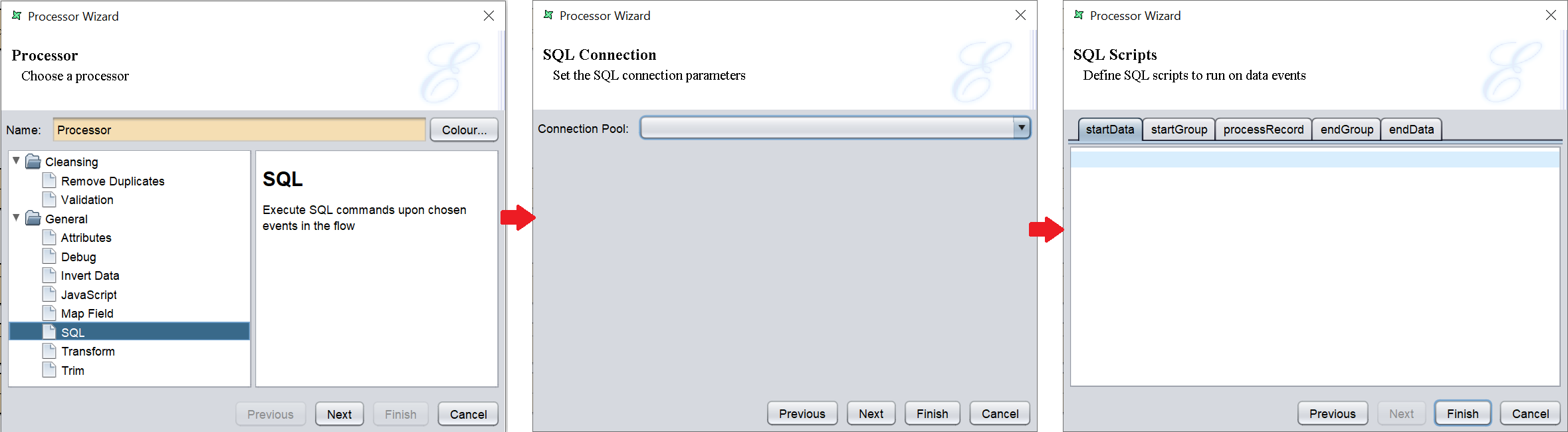
The output of the SQL processor is the same as the input and records passing through are not being modified as the user us only interacting with the database. With this, the user can load data in bulk into the database faster.
Transform
This task allows you to transform the values of the fields.
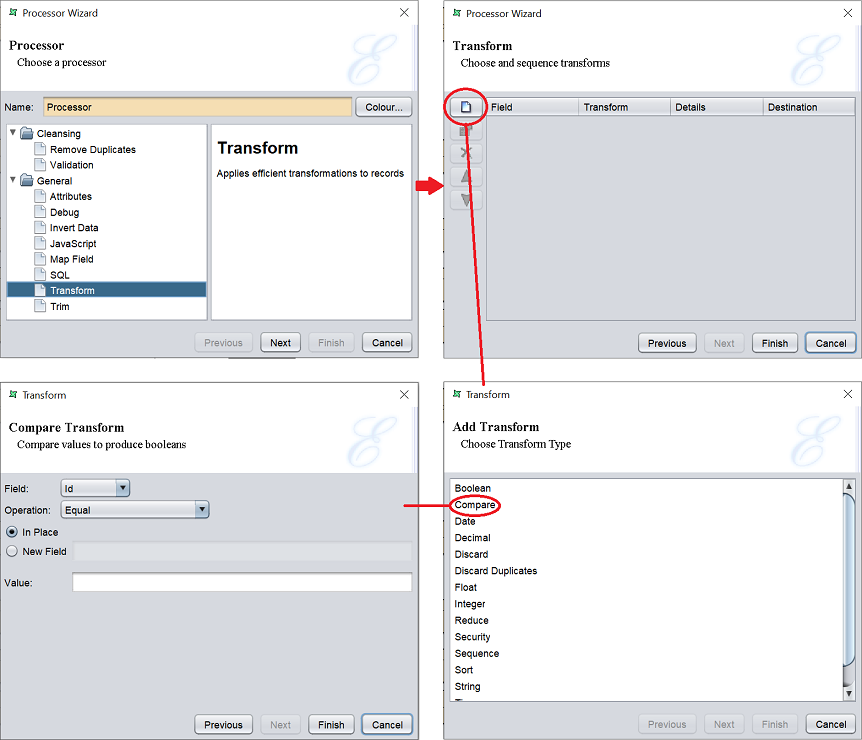
Select the field that needs to be transformed and select the desired operation. Different operation will require different settings. The screenshot above shows the fields required for the “Compare” operation.
Trim
This task removes the leading and trailing spaces of string data.
Delete Processor
To remove the Processor, simply select the Processor and click on the “delete” key on your keyboard. Alternatively, right-click on the Processor to display the pop-up menu and select “Delete Graphic” option.
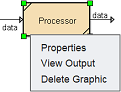
Pop-up Menu
To access the pop-up menu of the Processor, right-click on the processor.
There are three functions in the pop-up menu.
| Function | Description |
|---|---|
| Properties | Launches the Processor Wizard that allows you to edit the task of the Processor. |
| View Output | Switches to the “Data” tab, which displays the records of the datasource after the processing operation. |
| Delete Graphic | Deletes the Processor. |